

As part of the major restructuring of the internals of my ZPE project, I rewrote the whole parser. Before I explain what's changed with it, let me explain how ZPE works (and still does).
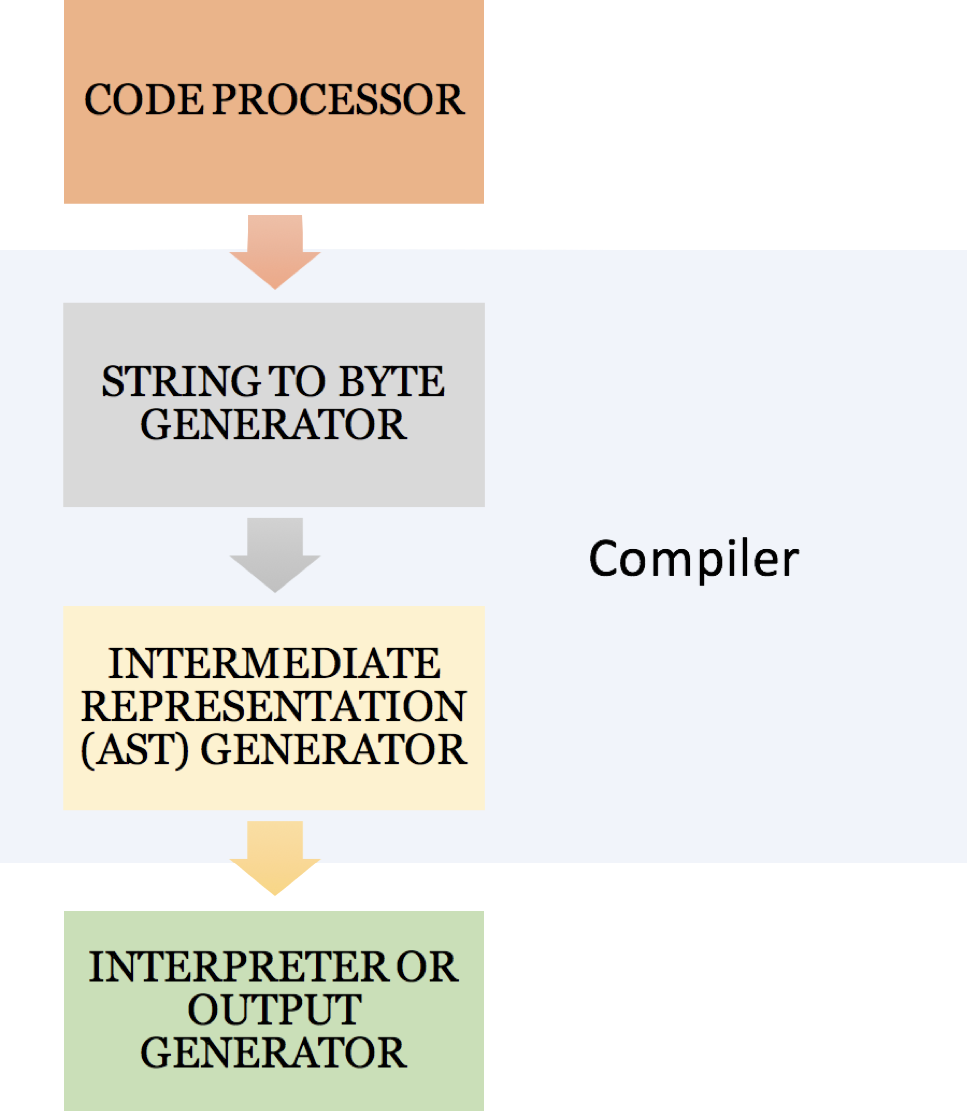
The previous image shows precisely how everything interacts. The second step is the most crucial, at least I see it that way. I say this because this is how my latest project functions. The project was known as Project Diamond originally, and I have no idea why I chose to name it that. This project looked at a new way of making the ZPE parser flexible and as a result ended up with me rewriting the whole ZPE parser (it's not that big though, only about 100 odd lines). Because of this rewrite it can be used to parse any language with minimal effort. Simply including the parser and requesting it does an action (such as eat a word) or return something (such as the current symbol or the current word) is all that is needed to write a programming language using it.
As a result of this, I wrote JBSON, which is my JSON parser. It works using my ZenithParser which is now fully open to use. It's very easy to use and I will share the source code of JBSON. Whilst JBSON is actually part of the ZPE package, it can be used completely separately and the whole ZPE package is not that heavy. However, as I am restructuring ZPE's internals I may make it a public library that's not a part of ZPE. The main motivation behind doing this was the Google's JSON was too big for ZPE, adding it doubled the size of the distributable JAR file.
